By Vihar Kurama and Shaoni Mukherjee

Introduction
Today, machine learning is the premise of big innovations and promises to continue enabling companies to make the best decisions through accurate predictions. But what happens when these algorithms’ error susceptibility is high and unaccountable?
Not all time machine learning models start strong—but what if we combine several weak models to create one strong model that performs much better? That’s exactly what AdaBoost, short for Adaptive Boosting, does. It’s a powerful ensemble learning technique that boosts the accuracy of predictions by focusing on the mistakes made by previous models. In this article, we will understand a powerful ensemble learning technique that helps boost the model’s performance.
Key takeaways:
- AdaBoost (Adaptive Boosting) is an ensemble technique that boosts the accuracy of a weak learner by training a sequence of models, each one paying more attention to the data points misclassified by the previous ones, and then combining all their predictions through a weighted vote to form a final strong classifier.
- In AdaBoost, each training example is assigned a weight that increases if it’s misclassified, so the algorithm focuses increasingly on “hard” cases, and each weak learner (often a simple decision tree stump) is given a weight in the final vote proportional to its accuracy—ensuring more reliable learners have a bigger say in predictions.
- This iterative focusing produces a powerful model from many simple ones, though AdaBoost can be sensitive to noise and outliers since it will magnify their influence if they cause repeated errors; however, on clean data, AdaBoost can substantially improve performance over any of the individual learners alone.
- AdaBoost was one of the first successful boosting algorithms and laid the groundwork for later methods like Gradient Boosting and XGBoost, so understanding how it adaptively combines models to minimize errors provides insight into why boosting is such a strong technique in machine learning.
Prerequisites
In order to follow along with this article, you will need experience with Python code and a basic understanding of classical machine learning. We will assume that all readers have access to sufficiently powerful machines so they can run the code provided.
Now, anyone can get access to powerful GPUs through the cloud. Many providers offer GPU-enabled services, and now, DigitalOcean GPU Droplets are available to everyone. Learn more and register your interest in GPU Droplets today!
For instructions on getting started with Python code, try this beginner’s guide to set up your system and prepare to run beginner tutorials.
What Is Ensemble Learning?
Ensemble learning combines several base algorithms to form one optimized predictive algorithm. For example, a typical Decision Tree for classification takes several factors, turns them into rule questions, and given each factor, either makes a decision or considers another factor. The result of the decision tree can become ambiguous if there are multiple decision rules, e.g., if the threshold to make a decision is unclear or we input new sub-factors for consideration. This is where Ensemble Methods come at one’s disposal. Instead of being hopeful on one Decision Tree to make the right call, Ensemble Methods take several different trees and aggregate them into one final, strong predictor.
Types Of Ensemble Methods
Ensemble Methods can be used for various reasons, mainly to:
- Decrease Variance
- Decrease Bias
- Improve Predictions
Ensemble Methods can also be divided into two groups:
- Sequential Learners, where different models are generated sequentially and the mistakes of previous models are learned by their successors. This aims at exploiting the dependency between models by giving the mislabeled examples higher weights (e.g., AdaBoost).
- Parallel Learners, where base models are generated in parallel. This exploits the independence between models by averaging out the mistakes.
Boosting in Ensemble Methods
Just as humans learn from their mistakes and try not to repeat them further in life, the Boosting algorithm tries to build a strong learner (predictive model) from the mistakes of several weaker models. You start by creating a model from the training data. Then, you create a second model from the previous one by trying to reduce the errors from the previous model. Models are added sequentially, each correcting its predecessor, until the training data is predicted perfectly or the maximum number of models has been added.
Boosting tries to reduce the bias error that arises when models are unable to identify relevant trends in the data. This happens by evaluating the difference between the predicted value and the actual value.
Types of Boosting Algorithms
- AdaBoost (Adaptive Boosting)
- Gradient Tree Boosting
- XGBoost
In this article, we will be focusing on the details of AdaBoost, which is perhaps the most popular boosting method.
Unraveling AdaBoost
AdaBoost (Adaptive Boosting) is a widely used boosting method that combines several weak classifiers into a single, powerful one. Yoav Freund and Robert Schapire originally introduced this technique.
A single classifier may not be able to accurately predict the class of an object, but when we group multiple weak classifiers with each one progressively learning from the others’ wrongly classified objects, we can build one such strong model. The classifier mentioned here could be any of your basic classifiers, from Decision Trees (often the default) to Logistic Regression, etc.
Now we may ask, what is a “weak” classifier? A weak classifier performs better than random guessing, but still performs poorly at designating classes to objects. For example, a weak classifier may predict that everyone above the age of 40 cannot run a marathon, but people falling below that age could. Now, you might get above 60% accuracy, but you would still be misclassifying a lot of data points!
Rather than being a model in itself, AdaBoost can be applied to any classifier to learn from its shortcomings and propose a more accurate model. For this reason, it is usually called the “best out-of-the-box classifier.”
Let’s try to understand how AdaBoost works with Decision Stumps. Decision Stumps are like trees in a Random Forest, but not “fully grown.” They have one node and two leaves. AdaBoost uses a forest of such stumps rather than trees.
Stumps alone are not a good way to make decisions. A full-grown tree combines the decisions from all variables to predict the target value. A stump, on the other hand, can only use one variable to make a decision. Let’s try and understand the behind-the-scenes of the AdaBoost algorithm step-by-step by looking at several variables to determine whether a person is “fit” (in good health) or not.
An Example of How AdaBoost Works
Step 1: A weak classifier (e.g., a decision stump) is made on top of the training data based on the weighted samples. Here, the weights of each sample indicate how important it is to be correctly classified. Initially, for the first stump, we give all the samples equal weights.
Step 2: We create a decision stump for each variable and see how well each stump classifies samples into their target classes. For example, in the diagram below, we check for Age, Eating Junk Food, and Exercise. We’d look at how many samples are correctly or incorrectly classified as Fit or Unfit for each stump.
Step 3: More weight is assigned to the incorrectly classified samples so that they’re classified correctly in the next decision stump. Weight is also assigned to each classifier based on its accuracy, which means high accuracy = high weight!
Step 4: Reiterate from Step 2 until all the data points have been correctly classified, or the maximum iteration level has been reached.
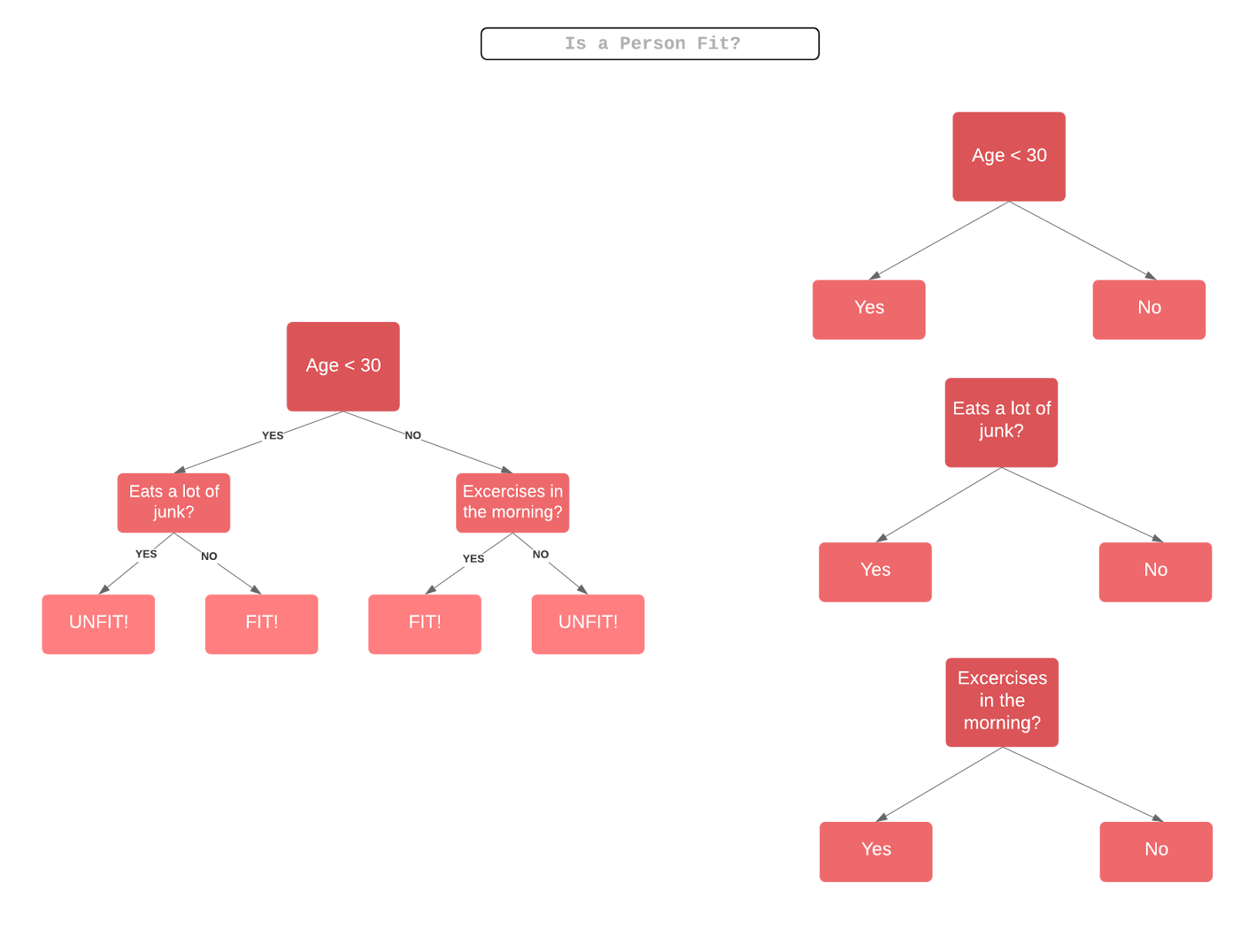
Fully grown decision tree (left) vs three decision stumps (right)

Note: Some stumps get more say in the classification than other stumps.
The Mathematics Behind AdaBoost
Here comes the hair-tugging part. Let’s break AdaBoost down, step-by-step and equation-by-equation, so that it’s easier to comprehend.
Let’s start by considering a dataset with N points, or rows, in our dataset.

In this case,
- n is the dimension of real numbers, or the number of attributes in our dataset
- x is the set of data points
- y is the target variable, which is either -1 or 1 as it is a binary classification problem, denoting the first or the second class (e.g., Fit vs Not Fit)
We calculate the weighted samples for each data point. AdaBoost assigns weight to each training example to determine its significance in the training dataset. When the assigned weights are high, that set of training data points is likely to have a larger say in the training set. Similarly, when the assigned weights are low, they have a minimal influence on the training dataset.
Initially, all the data points will have the same weighted sample w:

Where N is the total number of data points.
The weighted samples always sum to 1, so the value of each weight will always lie between 0 and 1. After this, we calculate the actual influence for this classifier in classifying the data points using the formula:

Alpha is how much influence this stump will have in the final classification. Total Error is nothing but the total number of misclassifications for that training set divided by the training set size. We can plot a graph for Alpha by plugging in various values of Total Error ranging from 0 to 1.
 Alpha vs Error Rate (Source: Chris McCormick)
Alpha vs Error Rate (Source: Chris McCormick)
Notice that when a Decision Stump does well, or has no misclassifications (a perfect stump!), this results in an error rate of 0 and a relatively large, positive alpha value.
If the stump just classifies half correctly and half incorrectly (an error rate of 0.5, no better than random guessing!), then the alpha value will be 0. Finally, when the stump ceaselessly gives misclassified results (just do the opposite of what the stump says!), then the alpha would be a large negative value.
After plugging in the actual values of Total Error for each stump, it’s time for us to update the sample weights, which we had initially taken as 1/N for every data point. We’ll do this using the following formula:

In other words, the new sample weight will be equal to the old sample weight multiplied by Euler’s number, raised to plus or minus alpha (which we just calculated in the previous step).
The two cases for alpha (positive or negative) indicate:
- Alpha is positive when the predicted and the actual output agree (the sample was classified correctly). In this case, we decrease the sample weight from what it was before, since we’re already performing well.
- Alpha is negative when the predicted output does not agree with the actual class (i.e, the sample is misclassified). In this case, we need to increase the sample weight so that the same misclassification does not repeat in the next stump. This is how the stumps are dependent on their predecessors.
Pseudocode of AdaBoost
Initially set uniform example weights.
for Each base learner do:
Train base learner with a weighted sample.
Test base learner on all data.
Set learner weight with a weighted error.
Set example weights based on ensemble predictions.
end for
Implementation of AdaBoost Using Python
Step 1: Importing the Modules
Info: Experience the power of AI and machine learning with DigitalOcean GPU Droplets. Leverage NVIDIA H100 GPUs to accelerate your AI/ML workloads, deep learning projects, and high-performance computing tasks with simple, flexible, and cost-effective cloud solutions.
Sign up today to access GPU Droplets and scale your AI projects on demand without breaking the bank.
As always, the first step in building our model is to import the necessary packages and modules.
In Python, we have the AdaBoostClassifier and AdaBoostRegressor classes from the scikit-learn library. For our case, we would import AdaBoostClassifier (since our example is a classification task). The train_test_split method is used to split our dataset into training and test sets. We also import datasets, from which we will use the Iris Dataset.
from sklearn.ensemble import AdaBoostClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
Step 2: Exploring the data
You can use any classification dataset, but here we’ll use the traditional Iris dataset for a multi-class classification problem. This dataset contains four features about different types of Iris flowers (sepal length, sepal width, petal length, petal width). The target is to predict the type of flower from three possibilities: Setosa, Versicolor, and Virginica. The dataset is available in the scikit-learn library, or you can also download it from the UCI Machine Learning Library.
Next, we prepare our data by loading it from the datasets package using the load_iris() method and assigning it to the iris variable.
Further, we split our dataset into input variable X, which contains the features sepal length, sepal width, petal length, and petal width.
Y is our target variable, or the class that we have to predict: either Iris Setosa, Iris Versicolor, or Iris Virginica. Below is an example of what our data looks like.
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X)
print(Y)
Output:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
. . . .
. . . .
]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2]
Step 3: Splitting the data
Splitting the dataset into training and testing datasets is a good idea to see if our model is classifying the data points correctly on unseen data.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Here we split our dataset into 70% training and 30% test, which is a common scenario.
Step 4: Fitting the Model
Building the AdaBoost Model. AdaBoost takes a Decision Tree as its learner model by default. We make an AdaBoostClassifier object and name it abc. A few important parameters of AdaBoost are :
- base_estimator: It is a weak learner used to train the model.
- n_estimators: Number of weak learners to train in each iteration.
- learning_rate: It contributes to the weights of weak learners. It uses 1 as a default value.
abc = AdaBoostClassifier(n_estimators=50,
learning_rate=1)
We then go ahead and fit our object abc to our training dataset. We call it a model.
model = abc.fit(X_train, y_train)
Step 5: Making the Predictions
Our next step would be to see how good or bad our model is at predicting our target values.
y_pred = model.predict(X_test)
In this step, we take a sample observation and predict unseen data. Further, we use the predict() method on the model to check for the class it belongs to.
Step 6: Evaluating the model
The Model accuracy will tell us how many times our model predicts the correct classes.
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Output:
Accuracy:0.8666666666666667
You get an accuracy of 86.66%—not bad. You can experiment with various other base learners, like Support Vector Machine and Logistic Regression, which might give you higher accuracy.
Advantages and Disadvantages of AdaBoost
AdaBoost offers several benefits, notably its ease of use and reduced need for parameter adjustments compared to algorithms such as SVM. Furthermore, AdaBoost can be effectively combined with SVM. While theoretical evidence is lacking, AdaBoost is generally considered less susceptible to overfitting, potentially due to its stage-wise estimation, which slows down the learning process rather than optimizing all parameters simultaneously. For a more detailed mathematical explanation, refer to this link.
AdaBoost can improve the accuracy of weak classifiers, making it flexible. It has now been extended beyond binary classification and has found use cases in text and image classification as well.
A few Disadvantages of AdaBoost are :
Since the boosting technique learns progressively, it is important to ensure that you have quality data. AdaBoost is also extremely sensitive to Noisy data and outliers, so if you plan to use AdaBoost, it is highly recommended that you eliminate them.
AdaBoost has also been proven to be slower than XGBoost.
FAQ’s
Q: AdaBoost vs Gradient Boosting vs XGBoost: which ensemble method to choose?
Choose boosting algorithms based on dataset characteristics and requirements:
- AdaBoost works well for binary classification with clean data, simple to implement and understand, but sensitive to noise and outliers.
- Gradient Boosting offers more flexibility with different loss functions, handles regression and multi-class problems, provides better performance but requires more tuning.
- XGBoost delivers state-of-the-art performance with built-in regularization, parallel processing, and advanced features like early stopping.
- Performance: XGBoost typically outperforms AdaBoost by 5-15% on most datasets.
- Speed: AdaBoost is fastest to train, XGBoost uses optimized implementation for better scalability.
- Use cases: AdaBoost for simple binary problems, Gradient Boosting for flexibility, XGBoost for competitions and production systems requiring maximum accuracy.
Q: How to prevent overfitting in AdaBoost ensemble models?
Preventing AdaBoost overfitting requires several strategies: Early stopping by monitoring validation error and stopping when it starts increasing. Limit weak learners using fewer estimators (50-200 instead of 500+) to prevent overcomplication. Weak learner constraints using shallow decision trees (max_depth=1-3) or linear models to maintain simplicity. Learning rate reduction (shrinkage) to slow down adaptation and improve generalization. Cross-validation for hyperparameter tuning and performance estimation. Data cleaning to remove outliers and noise that AdaBoost amplifies. Regularization techniques like limiting sample weights or implementing weight smoothing. Ensemble pruning removing weak learners that contribute little to final performance. Monitor both training and validation error curves to detect overfitting early.
Q: What types of weak learners work best with AdaBoost?
Effective AdaBoost weak learners share specific characteristics: Decision stumps (single-split trees) are most common, providing interpretability and avoiding complex interactions. Shallow decision trees (max_depth=2-5) balance complexity and simplicity while capturing basic patterns. Linear models work well for linearly separable data and provide computational efficiency. Requirements: Weak learners should perform slightly better than random chance (>50% accuracy for binary classification). Avoid: Complex models like deep trees or neural networks that can overfit individually. Performance considerations: Simpler weak learners often produce better ensemble performance due to diversity and reduced overfitting. Implementation: Use scikit-learn’s DecisionTreeClassifier with max_depth=1 as default, experiment with max_depth=2-3 for complex datasets. Focus on weak learner diversity rather than individual accuracy for optimal ensemble performance.
Q: How to implement AdaBoost for multi-class classification problems?
AdaBoost multi-class implementation uses several approaches: AdaBoost.M1 extends binary AdaBoost by requiring weak learners with >50% accuracy on all classes, works when weak learners are sufficiently strong. AdaBoost.SAMME (Stagewise Additive Modeling Multi-class Exponential loss) handles weak learners with accuracy >1/K where K is number of classes. One-vs-Rest approach trains separate binary AdaBoost classifiers for each class. Implementation: Use scikit-learn’s AdaBoostClassifier with algorithm=‘SAMME’ for discrete weak learners or ‘SAMME.R’ for probability-based learners. Weak learner choice: Decision trees work well for multi-class scenarios. Performance: Multi-class AdaBoost typically requires more weak learners and careful hyperparameter tuning. Evaluation: Use multi-class metrics like macro/micro F1-score and confusion matrices for comprehensive performance assessment.
Q: What are real-world applications of AdaBoost in 2025?
AdaBoost applications in 2025 span multiple domains:
- Computer Vision: Face detection (original Viola-Jones algorithm), object recognition, and medical image analysis where interpretability matters.
- Finance: Credit scoring, fraud detection, and risk assessment where model transparency is crucial for regulatory compliance.
- Healthcare: Disease diagnosis, patient risk stratification, and treatment recommendation systems.
- Marketing: Customer segmentation, churn prediction, and recommendation systems.
- Quality Control: Manufacturing defect detection and process monitoring.
- Text Classification: Spam detection, sentiment analysis, and document categorization.
- Advantages: Model interpretability, robustness on small datasets, and excellent performance on tabular data.
- Modern relevance: While XGBoost often outperforms AdaBoost, AdaBoost remains valuable for applications requiring interpretability, regulatory compliance, or when working with limited data where simpler models generalize better.
Conclusion
In this article, we explored the AdaBoost algorithm—one of the foundational techniques in Ensemble Learning that significantly enhances the performance of weak learners. We started off by laying the groundwork with an overview of ensemble methods, clearly distinguishing between bagging and boosting approaches. With this context, we delved into the mechanics of AdaBoost, understanding how it iteratively focuses on misclassified samples to improve overall model accuracy.
We also discussed the advantages and limitations of AdaBoost. While it offers improved accuracy and is less prone to overfitting than many traditional models, it can be sensitive to noisy data and outliers. Nonetheless, its real-world applications—such as in facial recognition systems—underscore its robustness and versatility in practical scenarios.
To help you get hands-on, we provided a simple implementation in Python, which you can extend further for your own use cases. If you’re looking to experiment with AdaBoost or train more complex ensemble models at scale, consider leveraging cloud platforms like DigitalOcean. With GPU-optimized Droplets and easy-to-deploy machine learning environments, DigitalOcean allows data scientists and developers to build and train models efficiently without worrying about infrastructure overhead.
We hope this article has sparked your interest in exploring the world of boosting algorithms further. With the right tools and foundational knowledge, you’re well on your way to mastering ensemble methods for robust machine learning solutions.
References
http://mccormickml.com/2013/12/13/adaboost-tutorial/
https://machinelearningmastery.com/boosting-and-adaboost-for-machine-learning/
http://rob.schapire.net/papers/explaining-adaboost.pdf
https://hackernoon.com/under-the-hood-of-adaboost-8eb499d78eab
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.