By Jeff Fan and Anish Singh Walia

Update
Note: 1-Click Deploy of HUGS to DigitalOcean GPU Droplets was deprecated on September 30, 2025. Hugging Face no longer offers HUGS deployments, as the experiment was discontinued. More information can be found in the HUGS documentation.
For current AI inference solutions, explore DigitalOcean’s Serverless Inference offering.
Introduction
Hugging Face’s Generative AI Services (HUGS) makes deploying and managing LLMs easier and faster. Now, with DigitalOcean’s 1-Click deployment for HUGS on GPU Droplets, you can set up, scale, and optimize LLMs on a cloud infrastructure tailored for high performance. This guide walks you through deploying HUGS on a DigitalOcean GPU Droplet and integrating it with Open WebUI. It also explains why this setup is ideal for seamless, scalable LLM inference.
Prerequisites
- A DigitalOcean Cloud account.
- A GPU Droplet deployed and running, and another Droplet up and running to deploy and run the Open WebUI docker container.
- Familiarity with SSH and basic Docker commands.
- An SSH key for logging into your Droplet.
Step 1 - Create and Access Your GPU Droplet
-
Set up the Droplet:
Go to DigitalOcean’s Droplets page and create a new GPU Droplet. Under the Choose an Image tab, please select 1-Click Models and use one of the available Hugging Face images.
-
Access the Console:
Once your Droplet is ready, click on its name in the Droplets section and select Launch Web Console.
-
Please note the Message of the Day (MOTD): This contains the bearer token and inference endpoint for API access, which you’ll need later.

Step 2 - Start Hugging Face HUGS
Hugging Face HUGS will automatically start after the Droplet setup. To verify, check the status of the Caddy service managing the inference API:
sudo systemctl status caddy
[secondary_label Output
● caddy.service - Caddy
Loaded: loaded (/lib/systemd/system/caddy.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/caddy.service.d
└─override.conf
Active: active (running) since Wed 2024-10-30 10:27:10 UTC; 2min 58s ago
Docs: https://caddyserver.com/docs/
Main PID: 8239 (caddy)
Tasks: 17 (limit: 629145)
Memory: 48.8M
CPU: 73ms
CGroup: /system.slice/caddy.service
└─8239 /usr/bin/caddy run --config /etc/caddy/Caddyfile
Allow 5-10 minutes for the model to fully load.
Step 3 - Start Open WebUI
Launch Open WebUI using Docker on another Droplet. Please use the below docker command to run the Open WebUI docker container.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Once Open WebUI runs, access it at http://<your_droplet_ip>:3000.

Step 4 - Integrate HUGS with Open WebUI
To connect Open WebUI with Hugging Face HUGS:
-
Open Settings:
- In Open WebUI, click your user icon at the bottom left, then click Settings.
-
Go to Admin:
- Navigate to the Admin tab, then select Connections.

-
Set the Inference Endpoint:
- In the API link field, enter your Droplet’s IP followed by
/v1. If a specific port is required, include it, e.g.,http://<your_droplet_ip>/v1. - Use the API token from the MOTD for authentication.
- In the API link field, enter your Droplet’s IP followed by
-
Verify Connection:
- Click Verify Connection. A green light confirms a successful connection. Open WebUI will then auto-detect available models, such as
hfhgus/Meta-Llama.

- Click Verify Connection. A green light confirms a successful connection. Open WebUI will then auto-detect available models, such as
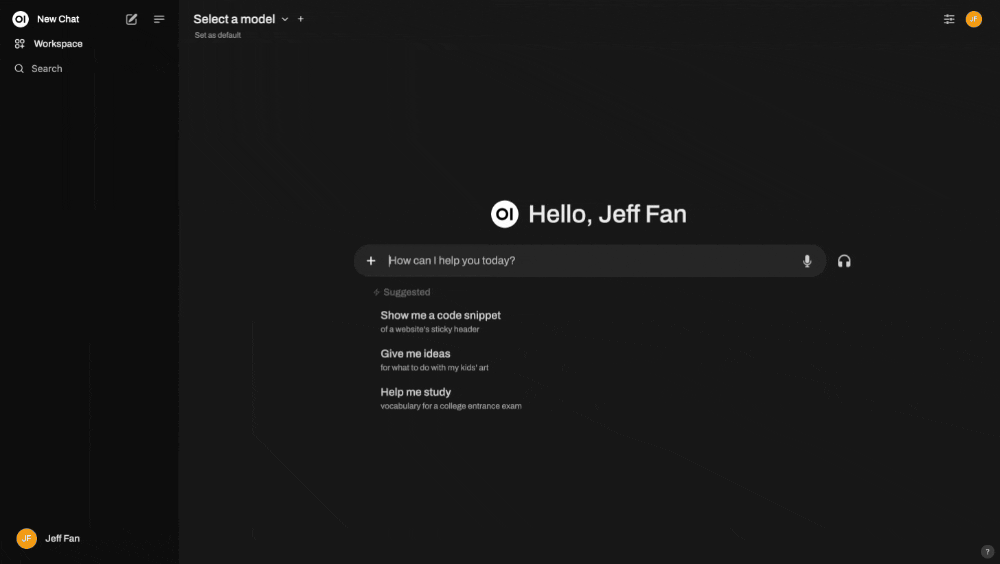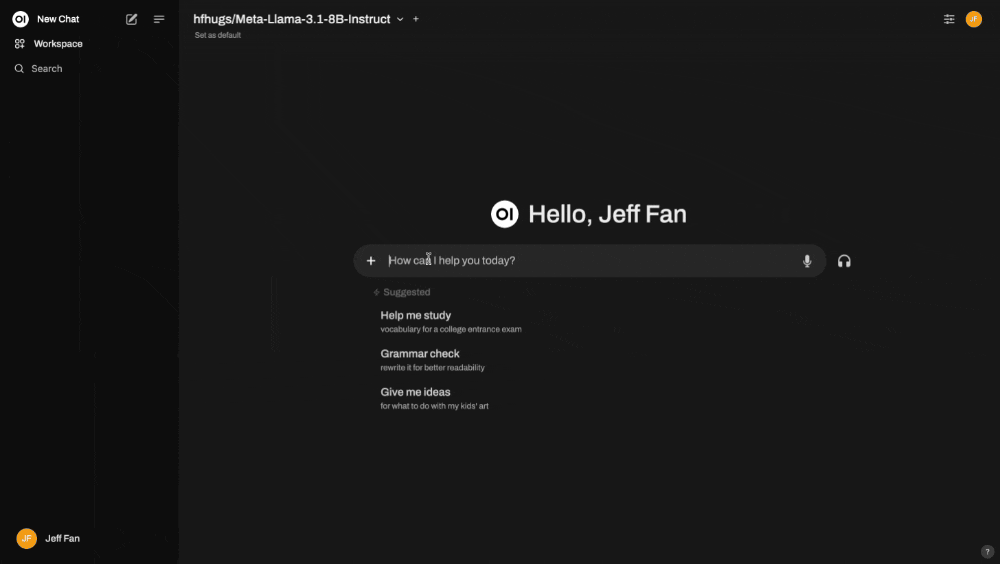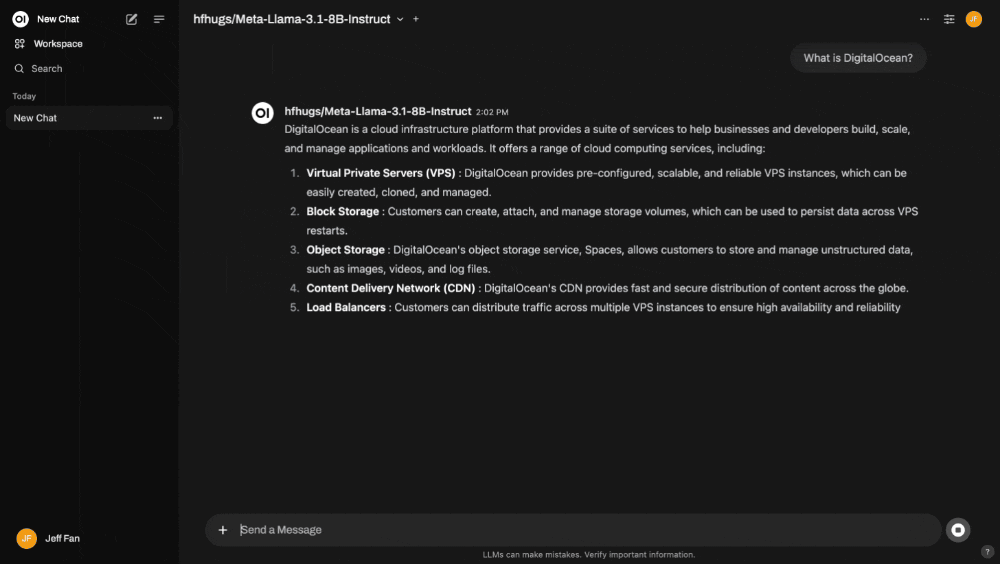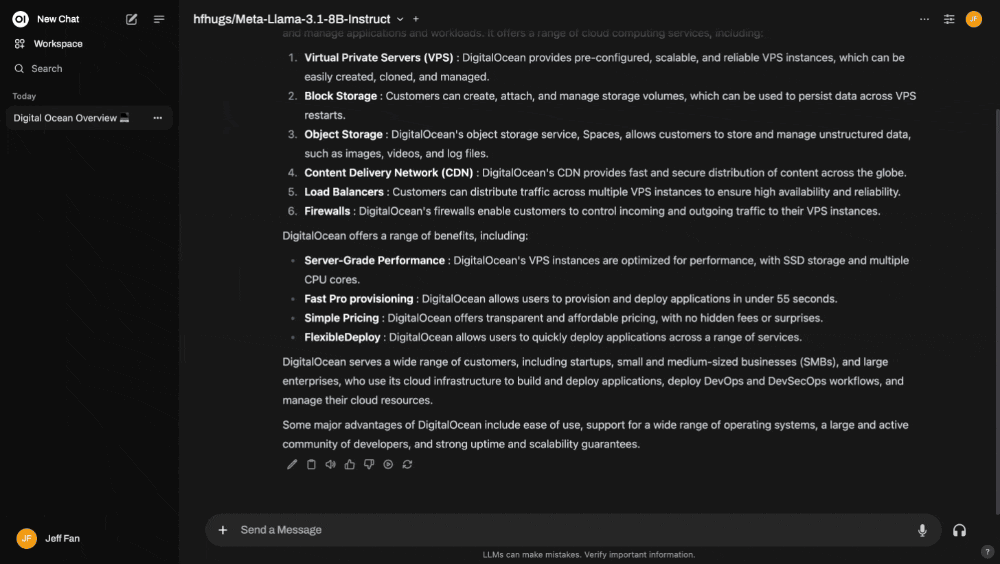
Step 5: Start Chatting with the Model
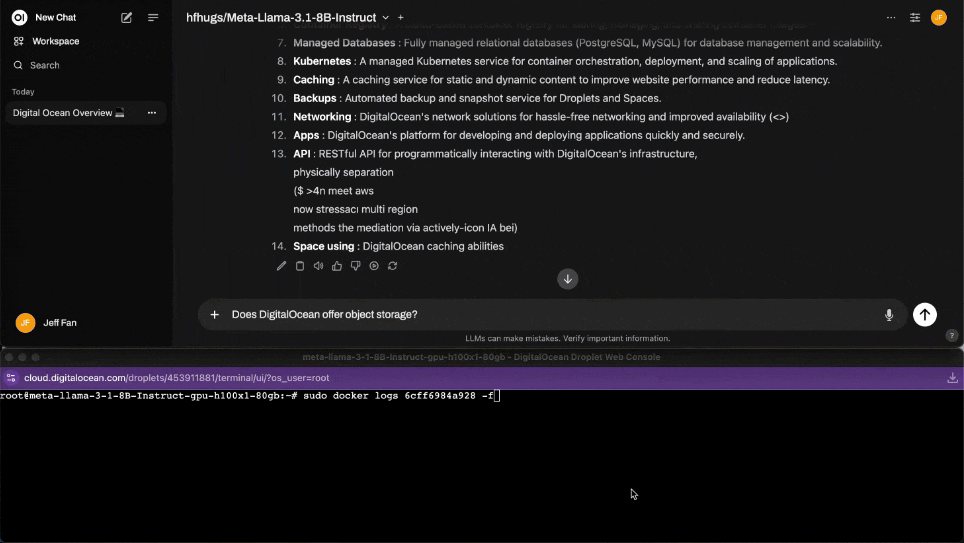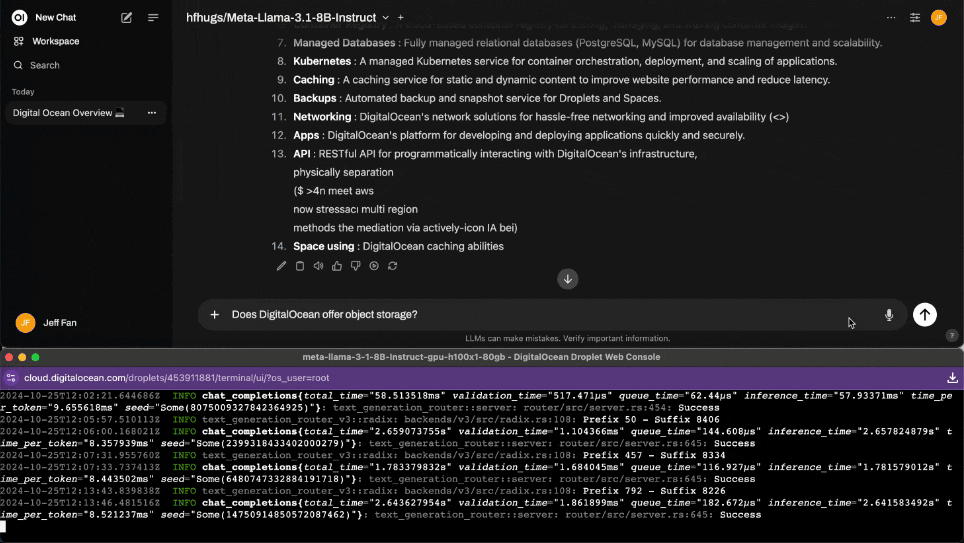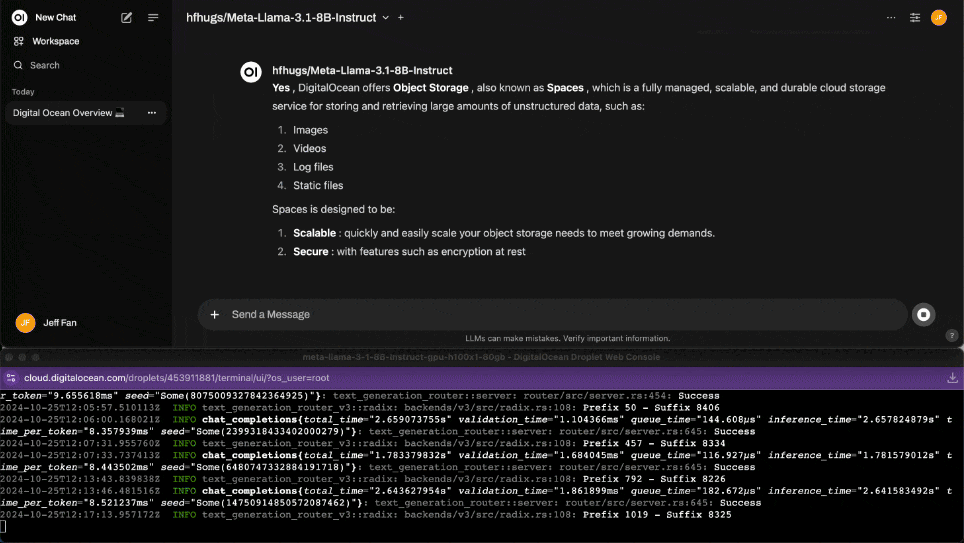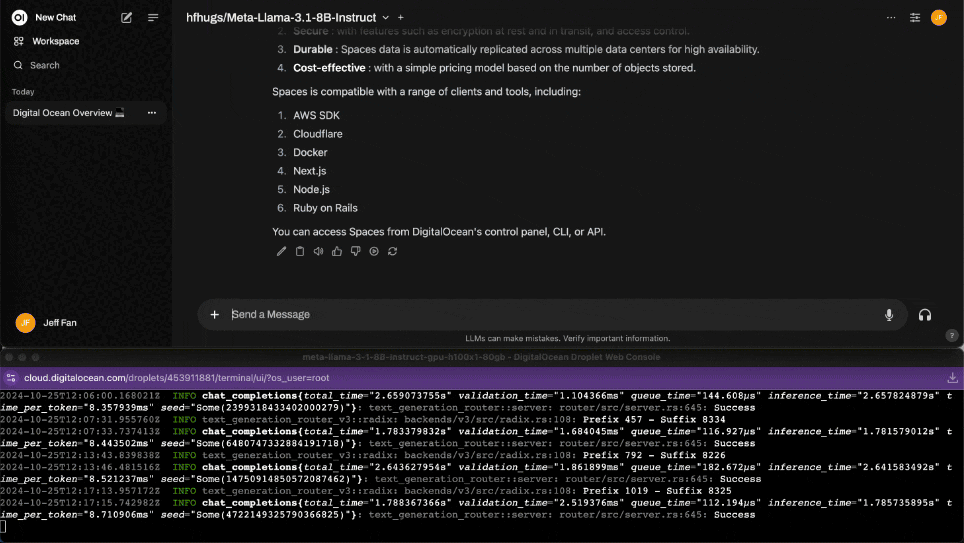
With HUGS integrated into Open WebUI, you’re ready to interact with your LLM:
- Ask questions like “What is DigitalOcean?”
- Monitor requests logs from the container while asking a follow-up question:
Does DigitalOcean offer object storage?:
sudo docker ps
sudo docker logs <your-container-ID> -f
Why Choose HUGS on DigitalOcean GPU Droplets?
-
Ease of Deployment and Simplified Management
Deploying HUGS with DigitalOcean’s one-click setup is straightforward. No need for manual configurations—DigitalOcean and Hugging Face handle the backend, allowing you to focus on scaling. -
Optimized Performance for Large-Scale Inference HUGS on DigitalOcean GPUs ensures optimal performance, running LLMs efficiently on GPU hardware without manual tuning.
-
Scalability and Flexibility DigitalOcean’s infrastructure supports scalable deployments with load balancers for high availability, letting you serve users globally with low latency.
By using Hugging Face HUGS on DigitalOcean GPU Droplets, you not only benefit from high-performance LLM inference but also gain the flexibility to scale and manage the deployment effortlessly. This combination of optimized hardware, scalability, and simplicity makes DigitalOcean an excellent choice for production-level AI workloads.
Conclusion
With HUGS deployed on DigitalOcean’s GPU Droplet and Open WebUI, you can efficiently manage, scale, and optimize LLM inference. This setup eliminates hardware optimization concerns and provides a ready-to-scale solution for delivering fast, reliable responses across multiple regions.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I’m a Senior Solutions Architect in Munich with a background in DevOps, Cloud, Kubernetes and GenAI. I help bridge the gap for those new to the cloud and build lasting relationships. Curious about cloud or SaaS? Let’s connect over a virtual coffee! ☕
I help Businesses scale with AI x SEO x (authentic) Content that revives traffic and keeps leads flowing | 3,000,000+ Average monthly readers on Medium | Sr Technical Writer @ DigitalOcean | Ex-Cloud Consultant @ AMEX | Ex-Site Reliability Engineer(DevOps)@Nutanix
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.