Technical Writer

Large Language Models (LLMs) are rapidly improving at reasoning, but long-context reasoning remains one of the hardest challenges. While pretraining has pushed context windows to hundreds of thousands of tokens, post-training techniques for reasoning across massive documents are still immature.
QwenLong-L1.5, released by Alibaba Tongyi Lab, addresses this gap with a complete post-training recipe that combines:
- Long-context data synthesis
- Reinforcement learning is designed for long sequences
- A memory management framework that goes beyond the model’s physical context window
In this article, we’ll explore:
- What makes QwenLong-L1.5 different
- Its memory-augmented reasoning architecture
- How to run QwenLong-L1.5 on a DigitalOcean GPU Droplet
- Practical inference code for long-context tasks
Key Takeaways
- QwenLong-L1.5 is designed specifically for long-context reasoning, addressing limitations that standard LLMs face when working with large documents or extended conversations.
- QwenLong-L1.5 is based on the Qwen3-30B-A3B-Thinking model, with strong reasoning and planning capabilities.
- Instead of relying on simple training tasks, it uses structured data synthesis and multi-hop reasoning challenges, which better reflect real-world use cases.
- The model introduces Adaptive Entropy-Controlled Policy Optimization (AEPO) to stabilize reinforcement learning on very long sequences.
- The model is trained with reinforcement learning techniques tailored for long sequences, including Adaptive Entropy-Controlled Policy Optimization (AEPO), which improves stability and learning efficiency.
- A multi-stage memory fusion framework allows the model to reason beyond its native 256K token window by summarizing, storing, and reusing information iteratively.
- These improvements not only enhance long-context tasks but also boost overall reasoning quality, including math, tool use, and dialogue coherence.
- While the model has a native context window of 256K tokens, its memory management framework allows it to effectively reason over information of virtually unlimited length.
What Is QwenLong-L1.5?
QwenLong-L1.5 is a long-context reasoning model built on Qwen3-30B-A3B-Thinking. It extends the base model through advanced post-training techniques that allow reasoning over documents far larger than 256K tokens, support multi-hop reasoning across globally distributed information, and maintain stable training even on extremely long input sequences.
Why Long-Context Post-Training Matters
Most LLMs fail not because they lack information, but because they:
- Lose track of earlier facts
- Fail multi-hop reasoning
- Collapse gradients during long-sequence RL
Core Innovations in QwenLong-L1.5
Long-Context Data Synthesis Pipeline
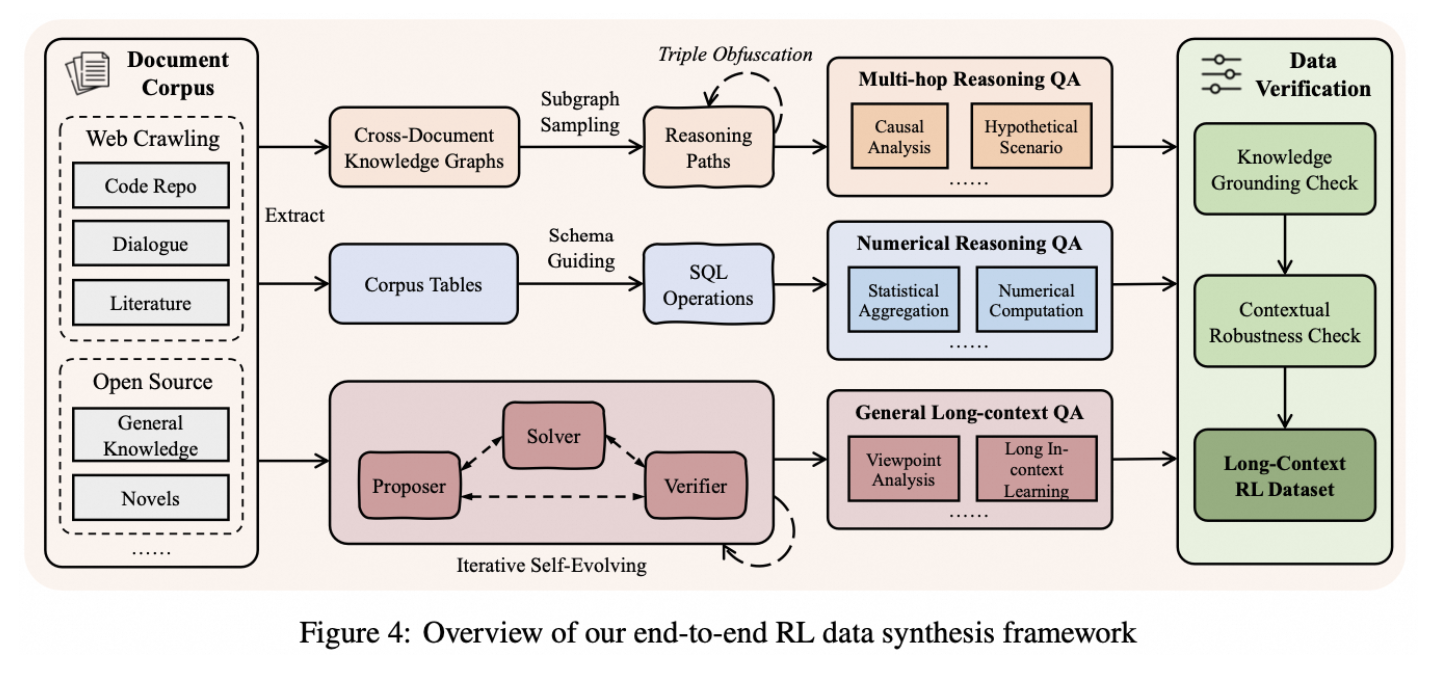
QwenLong-L1.5 improves long-context reasoning in three key ways: First, instead of using basic “find one fact” tasks, it creates smarter training data by breaking documents into small facts and building questions that require the model to connect information from many different parts of the text. Second, it uses specially designed reinforcement learning techniques to keep training stable when working with very long inputs, including a method called AEPO that carefully controls how the model learns as the text length increases. Finally, because some tasks are larger than what the model can read at once, it adds a memory system that lets the model summarize, store, and reuse important information over multiple steps, allowing it to reason effectively even beyond its normal context window.
Adaptive Entropy-Controlled Policy Optimization (AEPO)
Training on long sequences causes policy collapse in standard RL. QwenLong-L1.5 introduces AEPO, which:
- Dynamically adjusts entropy constraints
- Prevents gradient explosion
- Enables curriculum learning on increasing sequence lengths
Memory Management Beyond the Context Window
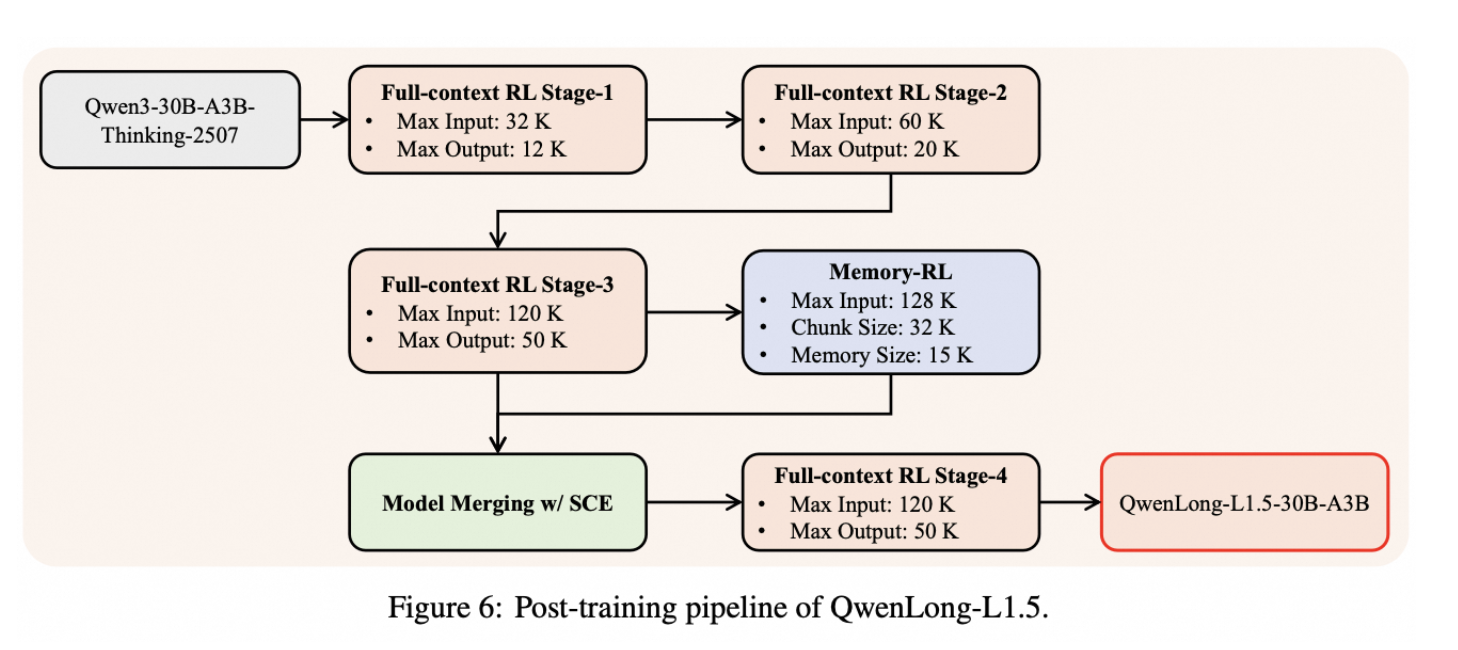
QwenLong-L1.5 introduces a multi-stage memory fusion framework to enable reasoning over information that far exceeds its native 256K token context window. In the first stage, the model performs single-pass reasoning over a large chunk of text within its available context, extracting key signals and intermediate reasoning results. These important details are then summarized and compressed into a structured memory representation, which preserves essential facts while removing redundant information.
In the next stage, this memory is iteratively updated as the model processes new segments of the document, allowing previously learned information to be refined, expanded, or corrected over time. Finally, a fusion-based reinforcement learning (RL) approach aligns the model’s reasoning process with its memory updates, ensuring that the stored memory directly supports accurate reasoning rather than drifting or becoming irrelevant. Together, these stages allow QwenLong-L1.5 to read massive document streams, maintain coherence across long spans of text, and perform multi-step, iterative reasoning loops that would be impossible within a single context window alone.
QwenLong-L1.5 Performance
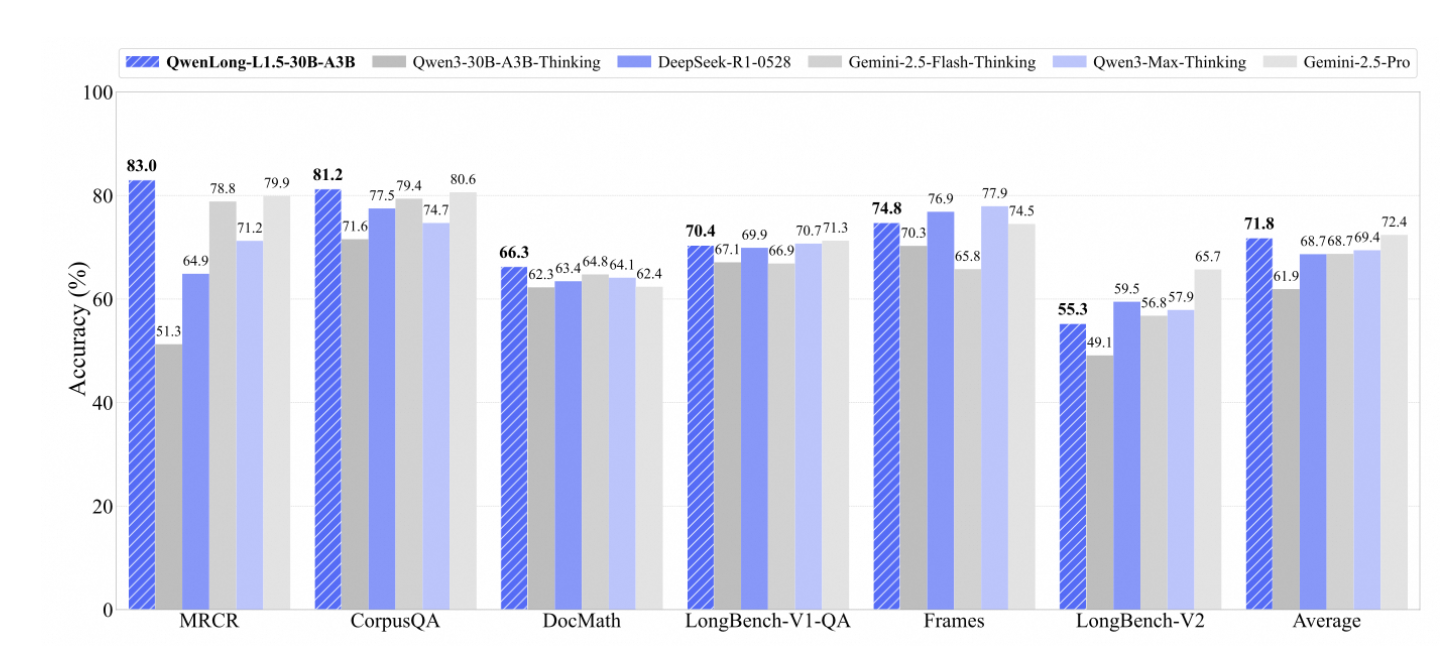
This benchmark comparison shows that QwenLong-L1.5-30B-A3B consistently outperforms its base model (Qwen3-30B-A3B-Thinking) and remains highly competitive with leading long-context models such as Gemini-2.5-Pro, Gemini-2.5-Flash-Thinking, DeepSeek-R1, and Qwen3-Max-Thinking. Across diverse long-context tasks, including multi-document reading comprehension (MRCR), CorpusQA, document-level math reasoning (DocMath), and LongBench evaluations, QwenLong-L1.5 demonstrates strong and balanced performance. Points to note here are that the model achieves significant gains on reasoning-heavy and memory-intensive benchmarks, such as LongBench-V1, Frames, and LongBench-V2, resulting in the highest or near-highest average accuracy overall. These results highlight how QwenLong-L1.5’s post-training strategies and memory fusion framework translate into reliable improvements for real-world long-context reasoning tasks, rather than gains limited to a single benchmark.
Why Run QwenLong-L1.5 on DigitalOcean GPUs?
DigitalOcean GPU Droplets are ideal for long-context inference because they offer:
- High-memory NVIDIA GPUs such as H100 and H200’s
- Predictable pricing
- Efficient and hassle-free GPU setup
- Full SSH & CUDA control
Recommended GPU Configuration
| Task | GPU |
|---|---|
| Inference | A100 / H100 |
| Long-context reasoning | H100 (recommended) |
Step 1: Create a DigitalOcean GPU Droplet
Start by creating a GPU Droplet on DigitalOcean to provide the compute resources required for running the model.
Choose:
- Image: Ubuntu 22.04
- GPU: H100 or A100
- 80GB VRAM (long contexts consume memory)
Feel free to check out the complete guide linked in the resources section to learn how to create a GPU Droplet on DigitalOcean.
Step 2: Environment Setup
Configure the system environment by installing the required drivers, libraries, and dependencies to ensure your GPU Droplet is ready for running and developing AI workloads.
# Update system
sudo apt update && sudo apt upgrade -y
# Install Python tools
sudo apt install -y python3-pip git
# Create virtual environment
python3 -m venv .venv
source .venv/bin/activate
Step 3: Install Dependencies
Install all necessary software packages, frameworks, and libraries required to run the model.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Verify Installation
python - <<EOF
import torch
print("Torch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
EOF
Step 4: Log in to Hugging Face
Authenticate with Hugging Face to access models, datasets, and tokens required for downloading and running pretrained models.
pip install -U huggingface_hub
hf auth login
Paste your Hugging Face access token when prompted (Generate it from: Hugging Face → Settings → Access Tokens)
Step 4: Download QwenLong-L1.5 on DigitalOcean GPU
Load the QwenLong-L1.5 model onto your DigitalOcean GPU Droplet
hf download Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
Step 5: Install verl
# Install verl, we use the 0.4 version of verl
git clone --branch v0.4 https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
Step 6: Start Using the Model
Load the QwenLong-L1.5 model and begin running inference or experiments to take advantage of its long-context reasoning capabilities.
# Load the model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
Use device_map="auto" to distribute weights efficiently across GPU memory.
Step 7: Long-Context Inference Example
Run an inference with input sequences to see how QwenLong-L1.5 handles long-context and multi-hop reasoning in practice.
Download a Long Novel from the Internet
import requests
url = "https://www.gutenberg.org/files/1342/1342-0.txt"
output_file = "novel.txt"
response = requests.get(url)
response.raise_for_status()
with open(output_file, "w", encoding="utf-8") as f:
f.write(response.text)
print("Novel downloaded successfully.")
Replace the URL with your own data source.
Load and Preprocess the Novel (Optional Step)
def load_novel(path):
with open(path, "r", encoding="utf-8") as f:
text = f.read()
# Optional cleanup
start_marker = "*** START OF"
end_marker = "*** END OF"
if start_marker in text:
text = text.split(start_marker)[-1]
if end_marker in text:
text = text.split(end_marker)[0]
return text.strip()
novel_text = load_novel("novel.txt")
print(f"Novel length (characters): {len(novel_text)}")
Build a Long-Context Prompt
question = (
"Who is the main protagonist of the novel, "
"and how does her personality evolve throughout the story?"
)
template = """
Please read the following novel and answer the question below.
<novel>
{novel}
</novel>
Question:
{question}
Format your response as:
"Therefore, the answer is (your answer here)"
"""
prompt = template.format(
novel=novel_text,
question=question
)
Tokenize and Run Inference
Long-context inference is GPU-intensive; hence, make sure you have enough GPU memory.
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(
[text],
return_tensors="pt"
).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=2000,
temperature=0.7,
top_p=0.95
)
Extract Reasoning and Final Answer
output_ids = outputs[0][len(inputs.input_ids[0]):].tolist()
try:
# token id for </think>
end_think_idx = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
end_think_idx = 0
thinking = tokenizer.decode(
output_ids[:end_think_idx],
skip_special_tokens=True
).strip()
final_answer = tokenizer.decode(
output_ids[end_think_idx:],
skip_special_tokens=True
).strip()
print("Reasoning:\n", thinking)
print("\nAnswer:\n", final_answer)
If the novel is too large even for 256K tokens, do this:
- Split the novel into chunks (e.g., chapters)
- Feed chunks sequentially
- Let QwenLong-L1.5 update memory internally
- Ask questions after processing all chunks
Real-World Use Cases
Applications that require comprehension and reasoning over vast amounts of data, like evaluating lengthy legal or financial documents, summarising and synthesising research papers, and powering conversational agents that must retain context over extended interactions, are well-suited for QwenLong-L1.5. It works well for creating enterprise knowledge assistants that integrate data from numerous documents to deliver precise, context-aware responses, as well as tool-using AI agents that must monitor instructions and outcomes across several steps.
FAQ’s
What is QwenLong-L1.5?
QwenLong-L1.5 is a long-context reasoning model developed by Alibaba Tongyi Lab, built on Qwen3-30B-A3B-Thinking and enhanced through post-training techniques focused on memory management and reinforcement learning.
How is QwenLong-L1.5 different from standard LLMs?
Unlike standard LLMs that struggle with very long inputs, QwenLong-L1.5 uses a memory framework and specialized training strategies to reason across documents that exceed its physical context window.
What is the maximum context length of QwenLong-L1.5?
The model has a native context window of 256K tokens, but its memory management framework allows it to effectively process information far beyond this limit.
Why use DigitalOcean GPUs for QwenLong-L1.5?
DigitalOcean GPU Droplets offer high-performance GPUs, predictable pricing, and easy setup, making them ideal for running large models like QwenLong-L1.5 in production or research environments.
Can QwenLong-L1.5 be used for general reasoning tasks?
Yes. Improvements in long-context reasoning also lead to better performance in general domains such as mathematics, tool usage, and long-form dialogue.
Conclusion
Strong long-context reasoning, as demonstrated by QwenLong-L1.5, depends not only on the size of the context window but also on how well a model is trained to reason, retain, and update information over time. QwenLong-L1.5 can handle complicated tasks involving large documents and lengthy interactions by combining structured data synthesis, specialised reinforcement learning techniques, and a multi-stage memory management framework. It becomes a workable and scalable solution for practical uses like document analysis, research synthesis, and enterprise knowledge assistants when implemented on DigitalOcean GPU Droplets. All things considered, QwenLong-L1.5 provides a potent, transparent method for long-context reasoning that yields excellent performance and practical usability in production settings.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.