Technical Writer

Introduction
Real-time object detection is at the core of modern computer vision applications, from autonomous vehicles to medical imaging to edge AI solutions. RF-DETR is a state-of-the-art detection transformer based model that delivers both high speed and high accuracy while adapting seamlessly to diverse domains. RF-DETR stands out by being the first real-time model to achieve 60+ mAP on COCO, while also excelling on RF100-VL, a benchmark built from 100 diverse datasets across real-world applications such as aerial imagery, industrial inspection, and nature studies.
With two sizes, RF-DETR-base (29M parameters) and RF-DETR-large (129M parameters); the model is designed to perform reliably whether you’re running experiments in the cloud, deploying on low-latency systems, or scaling for production. Object detection models face a challenge with evaluation. The widely used COCO benchmark, first introduced in 2014, hasn’t been updated since 2017, even though models have improved significantly and are now applied far beyond “common objects.” As a result, small mAP gains on COCO no longer tell the full story.
RF-DETR: not only compete on COCO but also emphasize two equally important factors: domain adaptability and speed. In real-world use, the ability of a model to adapt to new domains is just as critical as accuracy. To measure this, RF-DETR is evaluated across three dimensions:
- COCO mAP for standard benchmarking
- RF100-VL mAP, covering 100 diverse datasets from Roboflow Universe (used in real-world domains like aerial imagery, industry, and nature)
- Inference speed RF100-VL has been used by leading research labs at Apple, Microsoft, Baidu, and more. It ensures detectors are tested on the problems that matter most today. With these benchmarks, RF-DETR consistently ranks #1 or #2 compared to leading transformer models and CNNs (YOLO11, YOLOv8), proving both its accuracy and adaptability.
Key Points
- RF-DETR is built to deliver real-time performance without sacrificing accuracy or adaptability. Its design combines the latest advances in detection transformers with strong pre-training for better generalization across domains.
- RF-DETR builds on the efficient multi-scale attention mechanisms introduced in Deformable DETR, making transformer-based detection fast and practical.
- Unlike YOLO models, which need non-maximum suppression (NMS) as a post-processing step, RF-DETR produces final predictions directly, simplifying the pipeline and improving runtime efficiency.
- With multi-resolution training and lightweight architecture, RF-DETR can run efficiently on limited compute, making it suitable for both cloud-scale and on-device deployment.
Key Terms to Know
Non-Maximum Suppression (NMS): Non-Maximum Suppression is like a cleanup process for object detection results. When a model detects objects, it often finds the same object multiple times with slightly different bounding boxes. NMS keeps only the strongest detection (highest confidence) and removes the overlapping duplicates. Think of it as removing echoes so you hear only the original sound clearly. Traditional models like YOLO require this extra step, but RF-DETR is designed to avoid this post-processing, making it faster and more efficient.
Mean Average Precision (mAP): Mean Average Precision is the standard way to measure how good an object detection model is. It combines two important factors: how accurate the model’s predictions are (precision) and how many of the actual objects it finds (recall). The higher the mAP score (from 0 to 100), the better the model. When you see “RF-DETR achieves 60+ mAP on COCO,” it means the model correctly identifies and locates objects with high accuracy. It’s like a student’s test score, but for computer vision models.
Epochs: An epoch in machine learning is one complete pass through the entire training dataset. Think of it as reading a textbook from cover to cover once. Training for multiple epochs is like re-reading that textbook several times to better understand and remember the material. When fine-tuning RF-DETR, you might train for 15-50 epochs depending on your dataset size and desired accuracy. More epochs generally improve results but take longer and may eventually lead to overfitting (like memorizing the textbook without understanding the concepts).
Transformer Architecture: Transformers are a type of neural network architecture that uses a mechanism called “attention” to weigh the importance of different parts of the input data. Think of it like reading a sentence and knowing which words are most important for understanding the meaning. In RF-DETR, transformers help the model focus on relevant parts of an image when detecting objects. Unlike traditional convolutional neural networks (CNNs) that process images in a fixed pattern, transformers can learn relationships between any parts of an image regardless of distance, making them especially good at understanding context.
Batch Size: Batch size refers to the number of training examples (images) processed together in one forward/backward pass during training. It’s like cooking meals in batches rather than one at a time. A larger batch size can make training faster and more stable, but requires more GPU memory. When you see parameters like --batch_size 16 in RF-DETR training commands, it means the model will process 16 images at once. If you don’t have enough GPU memory, you can use gradient accumulation (explained below) to achieve a similar effect with smaller batches.
Gradient Accumulation: Gradient accumulation is a technique that allows you to train with effectively larger batch sizes than your GPU memory would normally allow. It works by processing smaller mini-batches and accumulating (adding up) their gradients before updating the model weights. It’s like saving up small amounts of money over time until you have enough to make a purchase. In RF-DETR training, the --grad_accum_steps parameter controls this behavior. For example, a batch size of 4 with 4 gradient accumulation steps is effectively similar to a batch size of 16.
Transfer Learning: Transfer learning is the technique of using knowledge gained from training on one task to improve performance on a different but related task. It’s like learning to ride a bicycle and then finding it easier to learn to ride a motorcycle. RF-DETR uses transfer learning through its pre-trained DINOv2 backbone, which has already learned to recognize visual patterns from millions of images. This allows RF-DETR to quickly adapt to new object detection tasks with relatively little training data.
COCO Format: COCO (Common Objects in Context) format is a standardized way to organize and store object detection datasets. It includes JSON files that describe images, categories, and annotations (like bounding boxes around objects). When the documentation mentions “RF-DETR expects COCO format,” it means your training data needs to follow this specific structure. Think of it as a universal language that allows different models to understand the same dataset. Most object detection datasets can be converted to COCO format, and tools like Roboflow make this process easier.
Bounding Box: A bounding box is a rectangular box that surrounds an object in an image. It’s defined by four values: the x and y coordinates of the top-left corner, and the width and height of the box. Think of it like drawing a rectangle around an object with a marker. In object detection, models like RF-DETR predict these bounding boxes to show where objects are located in an image. The accuracy of these boxes (how tightly they fit around the actual objects) is a key part of how object detection models are evaluated.
Learning Rate: Learning rate (often abbreviated as “lr” in code) controls how quickly a model updates its weights during training. It’s like adjusting the size of steps you take when walking toward a destination. A high learning rate means taking big steps, which can get you there faster but might cause you to overshoot. A low learning rate means taking small steps, which is more precise but slower. In RF-DETR training, you’ll see parameters like --lr 1e-4 (0.0001), which is a relatively small learning rate suitable for fine-tuning a pre-trained model. Finding the right learning rate is crucial for effective training.
Mixed Precision Training: Mixed precision training is a technique that uses both 16-bit and 32-bit floating-point numbers during training instead of just 32-bit. It’s like using both a rough sketch and a detailed drawing when needed. This approach can significantly speed up training and reduce memory usage without sacrificing accuracy. When the RF-DETR documentation mentions “use mixed precision (AMP) if available,” it’s referring to this technique. Modern GPUs, especially those designed for AI workloads, can perform 16-bit calculations much faster than 32-bit ones.
Inference: Inference refers to the process of using a trained model to make predictions on new data. It’s like taking a test after you’ve finished studying. In the context of RF-DETR, inference is when you use the model to detect objects in images or videos that it hasn’t seen during training. The term “inference speed” refers to how quickly the model can process new images and return results, which is crucial for real-time applications like video analysis or autonomous driving.
Backbone: In object detection models, the backbone is the part that extracts features from images. It’s like the foundation of a building that supports everything else. RF-DETR uses DINOv2 as its backbone, which is a pre-trained vision transformer that has learned to recognize patterns from millions of diverse images. The backbone processes the raw image and produces feature maps that the detection head then uses to locate and classify objects. A strong backbone is crucial for good performance, especially when adapting to new domains or working with limited training data.
Multi-Resolution Training: Multi-resolution training is a technique where a model learns to work with images of different sizes during training. It’s like teaching someone to read both large-print and small-print books. This allows RF-DETR to be flexible at inference time - you can run it with larger images for higher accuracy or smaller images for faster speed without needing to retrain the model. This is particularly useful when deploying the same model across different devices with varying computational capabilities, from powerful servers to resource-constrained edge devices.
Prerequisites
- GPU Environment: A CUDA-capable GPU (minimum 16GB VRAM recommended for training)
- Python: Version 3.9-3.11 (3.12 may require manual builds)
- PyTorch: Matching your CUDA version (verify with
torch.cuda.is_available()) - Conda Environment: Recommended for dependency management
- COCO Format Dataset: Required for training custom models
- API Keys: Roboflow API key if using their datasets or deployment services
- Basic Understanding: Familiarity with object detection concepts and transformer models
What is RF-DETR? RF-DETR Architecture Overview
RF-DETR (Roboflow-DETR) is a real-time object detection model built on the Detection Transformer (DETR) family of architectures. It is designed to combine the speed of YOLO models with the adaptability and pre-training advantages of transformers.
Unlike traditional CNN-based detectors, RF-DETR leverages a transformer backbone (DINOv2) and a lightweight DETR design (LW-DETR) to deliver:
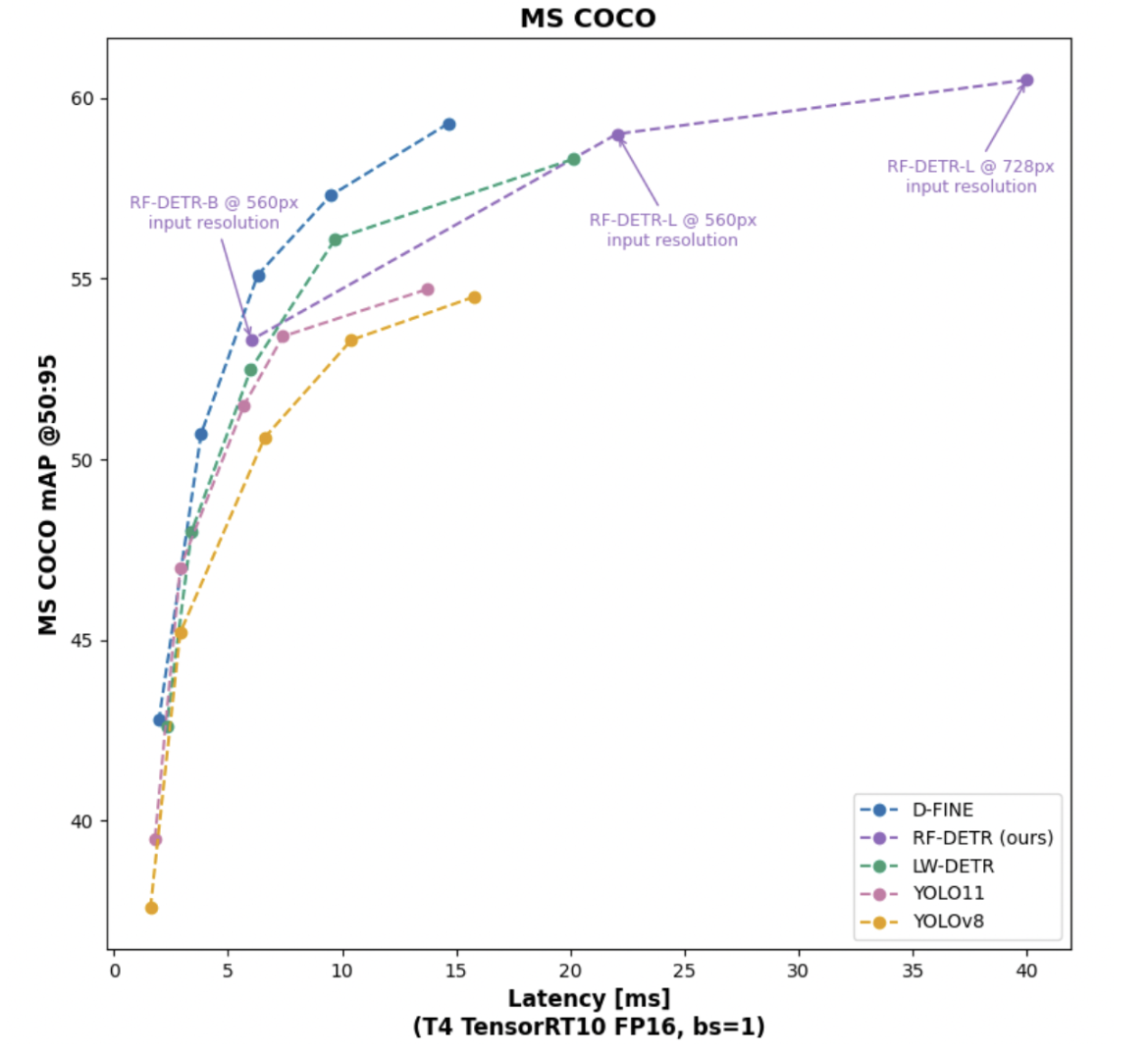
- High accuracy – the first real-time detector to cross 60+ mAP on COCO.
- Domain adaptability – strong performance on diverse datasets beyond COCO (like aerial, medical, and industrial imaging).
- Efficiency – runs in real-time, even on limited compute such as edge devices.
- Flexibility – supports multi-resolution inference, letting users balance speed and accuracy without retraining. Traditionally, YOLO models have set the standard for real-time object detection, thanks to their CNN-based design. However, CNNs don’t benefit as much from large-scale pre-training, which limits their adaptability and speed of convergence. On the other hand, transformers thrive with pre-training and show stronger performance in many machine learning tasks, but until recently, they were too large and slow for real-time detection.
- With the introduction of RT-DETR in 2023, transformers proved they could match YOLO’s speed, since DETRs avoid the extra NMS (non-maximum suppression) step required by YOLO. Recent improvements have also made DETRs train faster and generalize better, especially when paired with strong pre-trained backbones.
- RF-DETR builds on this progress. It is designed around the Deformable DETR architecture, but instead of multi-scale self-attention, it extracts image features from a single-scale backbone.
- To push performance further, we combined LW-DETR with a pre-trained DINOv2 backbone, giving RF-DETR the ability to adapt quickly to new domains with limited data. Another key feature is multi-resolution training, which allows the model to run at different input resolutions at inference time.
This gives users the flexibility to trade off accuracy and latency without retraining the model, hence ideal for both edge deployments and cloud-scale systems.
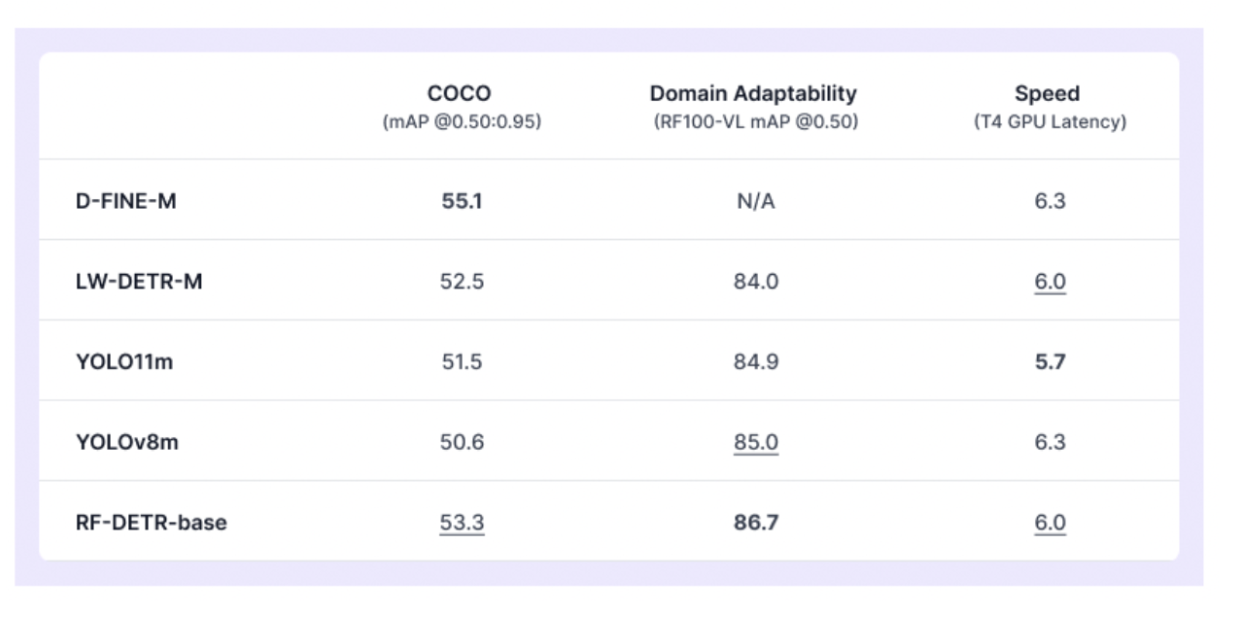
Why RF-DETR Matters in Object Detection?
-
COCO benchmark saturation: The standard COCO dataset that most object detection models are tested on has reached a point where improvements are minimal. This means new models like RF-DETR need to show they can work well across many different types of images and scenarios, not just on one benchmark. It’s like saying a car shouldn’t just perform well on one test track, but on all kinds of roads and weather conditions.
-
Generalization power: RF-DETR uses something called a DINOv2 backbone, which is like having a brain that’s already learned to recognize many visual patterns. This helps the model quickly adapt to new types of objects it hasn’t seen before. Think of it like a person who has traveled widely and can quickly understand new cultures, versus someone who has never left their hometown.
-
Flexibility: The model is trained to work with images of different sizes and qualities. This means you can choose to run it faster (with slightly lower accuracy) or more accurately (but slightly slower) without having to retrain the entire model. It’s similar to how a car can switch between eco mode for efficiency or sport mode for performance, depending on what you need at the moment.
Quick Guide: Run & Fine-Tune RF-DETR on a DigitalOcean Gradient™ AI GPU Droplets
You can quickly try out RF-DETR using the Inference server or the RF-DETR Python package. First, install the necessary dependencies:
pip install -q rfdetr==1.2.1 supervision==0.26.1 roboflow
The code below lets you run rfdetr-base on an image:
import os
import supervision as sv
from inference import get_model
from PIL import Image
from io import BytesIO
import requests
url = "https://media.roboflow.com/dog.jpeg"
image = Image.open(BytesIO(requests.get(url).content))
model = get_model("rfdetr-base")
predictions = model.infer(image, confidence=0.5)[0]
detections = sv.Detections.from_inference(predictions)
labels = [prediction.class_name for prediction in predictions.predictions]
annotated_image = image.copy()
annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
Create a GPU Droplet
- Plan: GPU Droplet with NVIDIA L40S (scale up if needed).
- Image: AI/ML Ready or Ubuntu 22.04 LTS.
- Networking: Enable SSH key for login. DigitalOcean GPU Droplets come with NVIDIA drivers, so you can start immediately.
Tip: If you plan to train Medium/Large models or use larger batch sizes, pick a droplet with more GPU memory (A100/H100 classes or equivalently large VRAM). For small experiments, a single GPU with 16GB can work (use gradient accumulation if VRAM is tight).
Create an isolated Python environment (Miniconda recommended)
# install Miniconda (if not using the AI image that already has it)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh # answer prompts (then reopen shell or `source ~/.bashrc`)
conda create -n rfdetr python=3.11 -y
conda activate rfdetr
pip install --upgrade pip
Install PyTorch that matches the CUDA version (use the official PyTorch instructions). Example (conda) for commonly used CUDA versions:
# Example for CUDA 11.8 (conda recommended)
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
# Or for CUDA 12.1 (if your image uses 12.1)
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia -y
Verifying torch.cuda.is_available() after installation is a good test.
Install RF-DETR and utility packages
From your activated env:
# core model and helpers
pip install rfdetr
# Roboflow Inference tools and dataset helpers
pip install inference supervision roboflow pillow requests
# optional: logging / experiment tracking
pip install wandb
# (if you want GPU-optimized inference server)
pip install inference-gpu
Get your dataset on the Droplet
Download from Roboflow programmatically (recommended if your dataset is on Roboflow):
# example (run in a python script or notebook)
from roboflow import Roboflow
rf = Roboflow(api_key="YOUR_ROBOFLOW_API_KEY")
project = rf.workspace().project("your-project-name") # or use roboflow.download_dataset helper
Simpler (as used in the notebook):
from roboflow import download_dataset
dataset = download_dataset("https://universe.roboflow.com/your-workspace/your-project/VERSION", "coco")
# dataset.location => path to local COCO-formatted dataset folder
(You must set ROBOFLOW_API_KEY env var or pass the key.) The RF-DETR notebook expects COCO format; the folder structure example is in the notebook.

Fine-tune RF-DETR — minimal Python script
Below is a copy-paste script based on your notebook. Save it as train_rfdetr.py file in your working directory.
# train_rfdetr.py
import argparse
from rfdetr import RFDETRMedium, RFDETRSmall, RFDETRNano, RFDETRBase
import os
MODEL_MAP = {
"nano": RFDETRNano,
"small": RFDETRSmall,
"medium": RFDETRMedium,
"base": RFDETRBase
}
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_dir", required=True)
parser.add_argument("--model_size", default="medium", choices=MODEL_MAP.keys())
parser.add_argument("--epochs", type=int, default=15)
parser.add_argument("--batch_size", type=int, default=8)
parser.add_argument("--grad_accum_steps", type=int, default=2)
parser.add_argument("--lr", type=float, default=1e-4)
parser.add_argument("--output_dir", default="output")
args = parser.parse_args()
ModelClass = MODEL_MAP[args.model_size]
model = ModelClass()
model.train(
dataset_dir=args.dataset_dir,
epochs=args.epochs,
batch_size=args.batch_size,
grad_accum_steps=args.grad_accum_steps,
lr=args.lr,
output_dir=args.output_dir
)
if __name__ == "__main__":
main()
Run it (example for medium model):
# in tmux/session
python train_rfdetr.py \
--dataset_dir /path/to/dataset \
--model_size medium \
--epochs 15 \
--batch_size 16 \
--grad_accum_steps 1 \
--lr 1e-4 \
--output_dir /path/to/output
If your GPU VRAM is limited, reduce batch_size and increase grad_accum_steps to keep the effective batch size similar (e.g., 4 × grad_accum_steps=4 => effective 16). The RF-DETR docs explicitly recommend this strategy. If you use W&B, set WANDB_API_KEY env var and the training will log to your W&B workspace.
Checkpoint → Inference → Optimize
After training finishes (or while training), load the best checkpoint and optimize for inference:
from rfdetr import RFDETRMedium
model = RFDETRMedium(pretrain_weights="/path/to/output/checkpoint_best_total.pth")
model.optimize_for_inference()
# then run model.predict(...) or use Inference server
You can also deploy to Roboflow Inference via model.deploy_to_roboflow(…) (you’ll need ROBOFLOW_API_KEY).
Practical tips & troubleshooting to fine-tune RF-DETR
- Match CUDA ↔ PyTorch: always verify nvidia-smi and then install PyTorch matching that CUDA version. Mismatches are a common source of torch.cuda errors.
- Out of memory: reduce batch_size, use grad_accum_steps, enable gradient_checkpointing=True (supported), and use mixed precision (AMP) if available. The RF-DETR library supports gradient checkpointing & early stopping.
- Python version: prefer 3.9–3.11
- Data format: RF-DETR expects COCO format; the notebook shows the directory layout. If using Roboflow, export as COCO and use the download_dataset helper.
- Multi-GPU: multi-GPU training requires NCCL configuration and distributed tooling; only follow that route once single-GPU runs are stable.
FAQ’s
-
What makes RF-DETR different from YOLO models? RF-DETR uses a transformer-based architecture instead of the traditional CNN approach used by YOLO. This means RF-DETR doesn’t need an extra step called NMS (Non-Maximum Suppression) that YOLO requires to filter duplicate detections. Think of it like having a smart assistant who directly gives you the final answer versus one who gives you multiple options that you then have to sort through yourself. This makes RF-DETR not only more efficient but also potentially more accurate since it’s designed to produce cleaner results from the start.
-
What hardware is recommended for training RF-DETR? For comfortable training, you’ll want a GPU with at least 16GB of memory (VRAM). It’s like needing enough counter space when cooking a complex meal - without enough space, you’ll have to work in smaller batches, which takes longer. If you’re working with larger models or bigger datasets, consider more powerful GPUs like the A100 or H100, which have much more memory. If you’re on a budget, you can still make it work with less powerful GPUs by reducing batch sizes and using techniques like gradient accumulation, but training will take longer.
-
Can RF-DETR be deployed on edge devices? Yes! RF-DETR is designed with efficiency in mind and comes in different sizes. The nano and small variants are specifically built for edge devices like smartphones, cameras, or small computers. It’s like having both SUV and compact car versions of the same vehicle - the smaller versions maintain the core benefits while fitting into tighter spaces. This makes RF-DETR versatile enough to run both in the cloud and on devices with limited computing power.
-
How long does it take to train RF-DETR on a custom dataset? Training time depends on several factors: your dataset size, the model variant you choose, and your hardware. On a good GPU, you might see decent results in just 10-15 epochs, which could take a few hours for a medium-sized dataset. It’s like learning a new skill - the basics come quickly, but mastery takes time. The good news is that RF-DETR leverages transfer learning from its pre-trained backbone, so it often converges faster than models that start from scratch. For production-quality results, you might want to train longer, potentially 50+ epochs.
-
Do I need a lot of data to fine-tune RF-DETR? One of RF-DETR’s strengths is that it can perform well even with limited data thanks to its pre-trained DINOv2 backbone. Think of it like a person who already knows several languages finding it easier to learn a new one. While more data generally leads to better results, you can get started with as few as a couple of hundred labeled images. For best results, aim for diverse examples that cover different lighting conditions, angles, and scenarios your model will encounter in the real world.
-
How does RF-DETR handle small objects compared to other detectors? RF-DETR performs particularly well on small objects thanks to its transformer architecture and multi-scale feature processing. Unlike some detectors that struggle with tiny objects, RF-DETR can maintain good detection rates across different object sizes. It’s similar to how some people can spot both large and small details in a painting, while others might miss the smaller elements. This makes RF-DETR especially valuable for applications like aerial imagery, medical scans, or industrial inspection, where small objects matter just as much as large ones.
-
Can I use RF-DETR for video processing? Absolutely! RF-DETR’s real-time performance makes it well-suited for video processing. Since it can run at high frame rates (especially the smaller variants), you can apply it to video streams for applications like surveillance, sports analysis, or autonomous navigation. For even better performance on videos, you could implement tracking algorithms alongside RF-DETR to maintain consistent object identities across frames. Some users also leverage RF-DETR’s multi-resolution capability to process keyframes at higher resolution while using lower resolution for intermediate frames to balance accuracy and speed.
Conclusion
RF-DETR represents a significant breakthrough in the field of object detection, bridging the gap between high-accuracy transformer models and real-time performance requirements. By combining the powerful pre-trained DINOv2 backbone with an efficient DETR architecture, RF-DETR delivers exceptional results across multiple dimensions:
- Speed without Sacrifice: RF-DETR achieves real-time inference speeds while maintaining high accuracy (60+ mAP on COCO), eliminating the traditional trade-off between speed and precision.
- Domain Adaptability: Unlike models that excel only on specific datasets, RF-DETR demonstrates remarkable versatility across diverse domains from aerial imagery to medical scans to industrial inspection.
- Resource Efficiency: With multiple model sizes (nano, small, medium, base), RF-DETR can be deployed on everything from powerful cloud servers to resource-constrained edge devices.
- Training Efficiency: Thanks to its pre-trained backbone, RF-DETR can be fine-tuned with relatively small datasets and converges faster than models that start from scratch.
RF-DETR is particularly well-suited for:
- Autonomous Systems: Self-driving vehicles, drones, and robots that require real-time object detection with high reliability.
- Medical Imaging: Detection of anomalies in X-rays, MRIs, and other medical scans where both speed and accuracy are critical.
- Industrial Automation: Quality control systems that need to detect defects or components on fast-moving production lines.
- Smart City Applications: Traffic monitoring, crowd analysis, and public safety systems that process multiple video streams simultaneously.
- Augmented Reality: Real-time object recognition for AR applications where low latency is essential for a seamless user experience.
Future Outlook
As transformer-based architectures continue to evolve, RF-DETR’s approach of combining pre-trained vision transformers with efficient detection heads points to a promising direction for computer vision. The model’s ability to balance accuracy, speed, and adaptability makes it not just a tool for today’s applications but a foundation for tomorrow’s innovations.
By deploying RF-DETR on DigitalOcean Gradient AI GPU Droplets, developers and researchers can quickly experiment, fine-tune, and scale their object detection solutions without the complexity of managing infrastructure. Whether you’re building a prototype or deploying to production, RF-DETR offers the flexibility and performance to meet your computer vision challenges head-on.
Reference
- DigitalOcean Gradient GPU Droplets how to create + AI/ML images.
- DigitalOcean recommended GPU setup drivers, scratch disk.
- RF-DETR docs install & training API.
- Roboflow guide: “How to train RF-DETR on a custom dataset” notebook walkthrough.
- PyTorch install pick the correct conda for your CUDA version.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.